David Zimmermann, PhD
Data Scientist
whoami
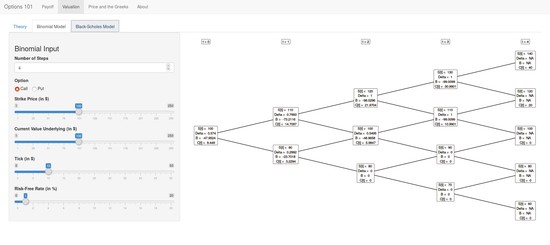
I am David Zimmermann, a data scientist from Cologne, Germany interested in solving real-world problems using machine learning, data science, and other appropriate measures. In my past, I did a PhD in computational finance, where I simulated financial markets using agent-based models to find the effects of high-frequency trading.
This blog was built with the intention to share different applications, tricks, and also some mild shenanigans with data, R, C++, Python, or other areas. If you have any comments, ideas, issues, or just want to give me a thumbs up, leave a note or write an email to david_j_zimmermann {at] hotmail [dot} com.
The source of this blog can be found on my .
Interests
- Data Science
- Machine Learning
- Programming
Education
-
PhD in Computational Finance, 2019
Universität Witten/Herdecke, Germany
-
MSc Finance & Investment, 2015
University of Edinburgh, UK
-
BA in Corporate Management & Economics (minor in Public Administration and International Relations), 2014
Zeppelin Universität, Germany